
Olvasási idő: 4 perc

Az angol nyelvű, technikailag részletesebb írásom a Towards Data Science oldalán olvasható a témában.
Bevezető
Az NLP (Natural Language Processing — természetes nyelvfeldolgozási) eszközök foglalják magukban azokat a módszereket, melyek lehetővé tették például az Amazonnak, hogy a termékekre leadott vélemények tömegéből megmondják, mi tetszik az embereknek és mi nem, vagy éppen melyeket a Twitter használ álhírek azonosítására a szövegek tartalmai, szóhasználatai, illetve mondatstruktúráik vizsgálatai által. A szövegbányászat erősségét egy hobbi-projekten keresztül szemléltetem, egy közismert sorozat szövegkönyvének elemzésén keresztül. A jó hír az, hogy a bemutatott módszereket a fent említetteknél sokkal kisebb cégek is alkalmazhatják saját üzletmenetük támogatására.
Akinek ismerős az amerikai The Office sorozat, annak a ’dundies’, ’Big Tuna’ vagy a ’wuphf’ rögtön jelentenek valamit, azt is tudja, kikhez fűzhetők a kifejezések. Az is köztudott, hogy Angela egy általánosságban negatívnak tekinthető személy, vagy, hogy Jim és Pam kapcsolata mesebeli módon pozitív az évadok nagyobb részében. Vajon a data science ezeket, a nézők által ismert tényeket képes adatelemzések útján megmutatni?
Kétrészes blogposztomban az elemzés során a szövegbányászat metódusait a szereplőnkénti szó- és szófordulat-gyakoriságok, egyedi szavak, egyéni és egymás közötti szentimentumok, illetve a hasonló szókincsek megtalálására használom fel. Az első részében a szereplők szóhasználataikra koncentrálok, míg a második epizódban a szentimentumokat vizsgálom és röviden bemutatom a ’hasonló szókincsű embereket’.
Olvasás során remélem, hogy az Natural Language Processing (NLP) csodás alkalmazási lehetőségeinek bemutatása mellett a The Office rajongók is egy nosztalgikus élményt szerezhetnek. Amint kedvenceikről olvashatnak, láthatják, miként képes az NLP megtalálni azon szavakat, melyekről egyértelműen beazonosítható egy-egy szereplő, illetve hogyan tudja bebizonyítani azt, hogy az emberek közötti viszonyok a használt szavak alapján majdnem tökéletesen kikövetkeztethetők.
Az elemzés során az R programnyelvet használtam, a következő csomagokra támaszkodva: (1) tidyverse és data.table adat-manipulációhoz, (2) tidytext, stringr, textdata, textstem, stopwords, sentimentr és topicmodels a konkrét szövegelemzéshez, illetve (3) ggplot, igraph és visnetwork a vizualizációkhoz.
Legtöbbet beszélő szereplők kiválasztása
Az Office fanok tudhatják, hogy ugyan megtalálható a ’fő’ stáblista, a teljes sorozatban azonban rengeteg további szereplővel találkozunk. Ahhoz, hogy befogadhatóbbá és átláthatóbbá váljanak az eredmények, limitálni kellett a vizsgált szereplők számát. A 12 legkommunikatívabb szereplő az elhangozott szövegek 80%-át mondja ki. Ez tehát az ismert 80-20 szabály egy jól alkalmazható esete.
Nézzük kikről is lesz szó:
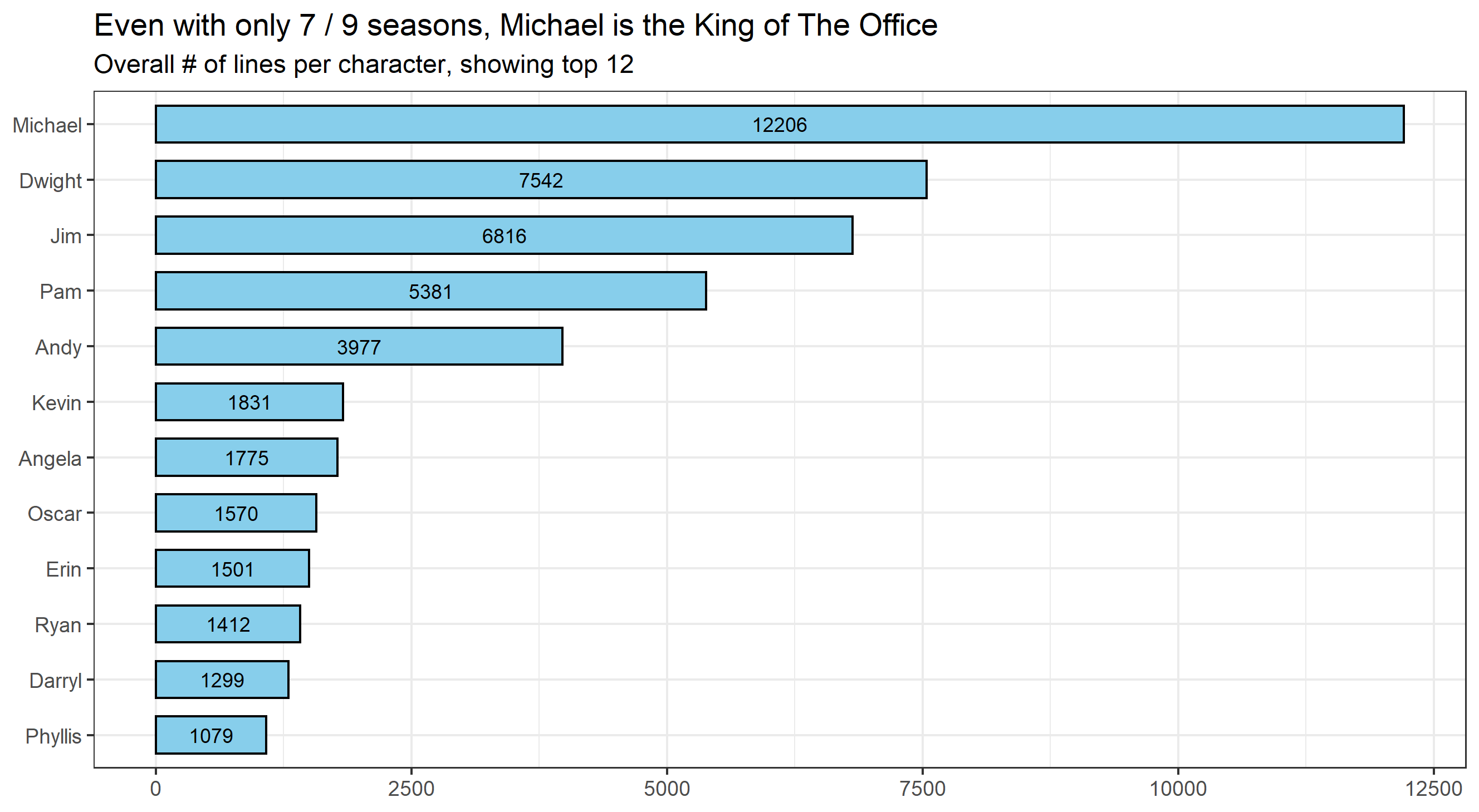
A fent olvasható karakterek szókincsét és egymás közti viszonyaikat taglaljuk a továbbiakban.
A diagramon például jól látszik, hogy Michael beszél a legtöbbet a teljes sorozatban, annak ellenére is, hogy az utolsó két évadban nem szerepelt. Évadonként megnézhetjük, hogy az előbb említett, sorozatot lezáró két évadban ki vette át Michael szerepét, a rá jutó sorok alapján.
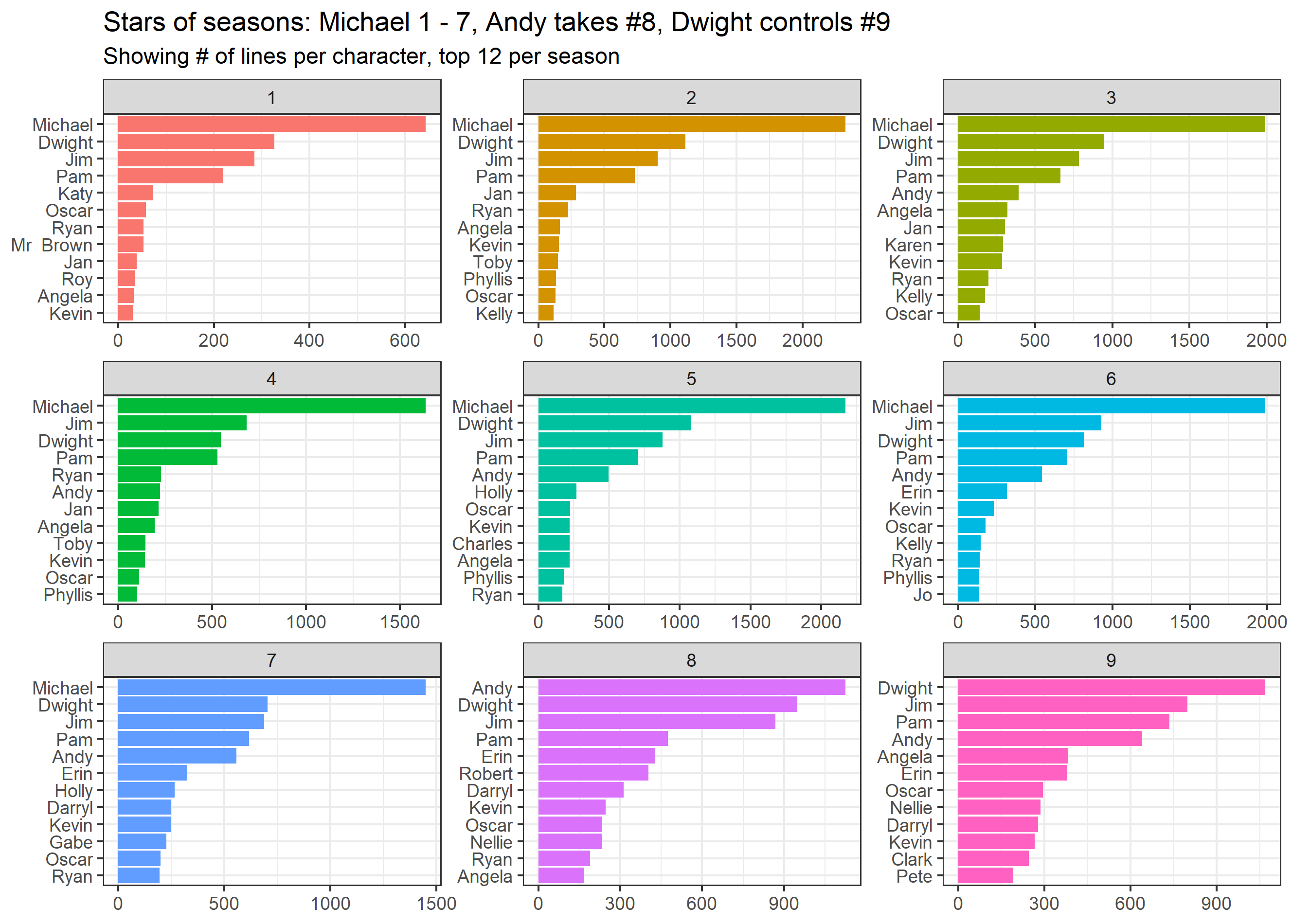
Andy, Dwight és Jim kaptak a záró évadokban nagyobb szerepet, azonban egyikük sem került olyan túlnyomó többségű helyzetbe, mint Michael a 7. évadig.
A leggyakrabban használt szavak és szókapcsolatok, legegyedibb szavak
A szereplők részletesebb megismeréséhez az általuk leggyakrabban használt szavakra vethetünk egy pillantást. Ezt, vagyis a szöveg egyéni szavak szintjére való bontását és ottani vizsgálódást tokenizációnak nevezi a szakma. Az eredmények közzététele előtt egy lényeges lépésre hívjuk fel a figyelmet: az úgy nevezett ’stopwords’ szavaktól való megszabadulásra. Ezek a szavak nem hordoznak információt, hanem a szövegkörnyezetet egészítik ki a folytonos kommunikáció eléréséhez. Ilyenek az ’én, te, hogy, mert, az, egy, stb…’.
Ezen szavak nélkül az alábbi eredményt kapjuk:
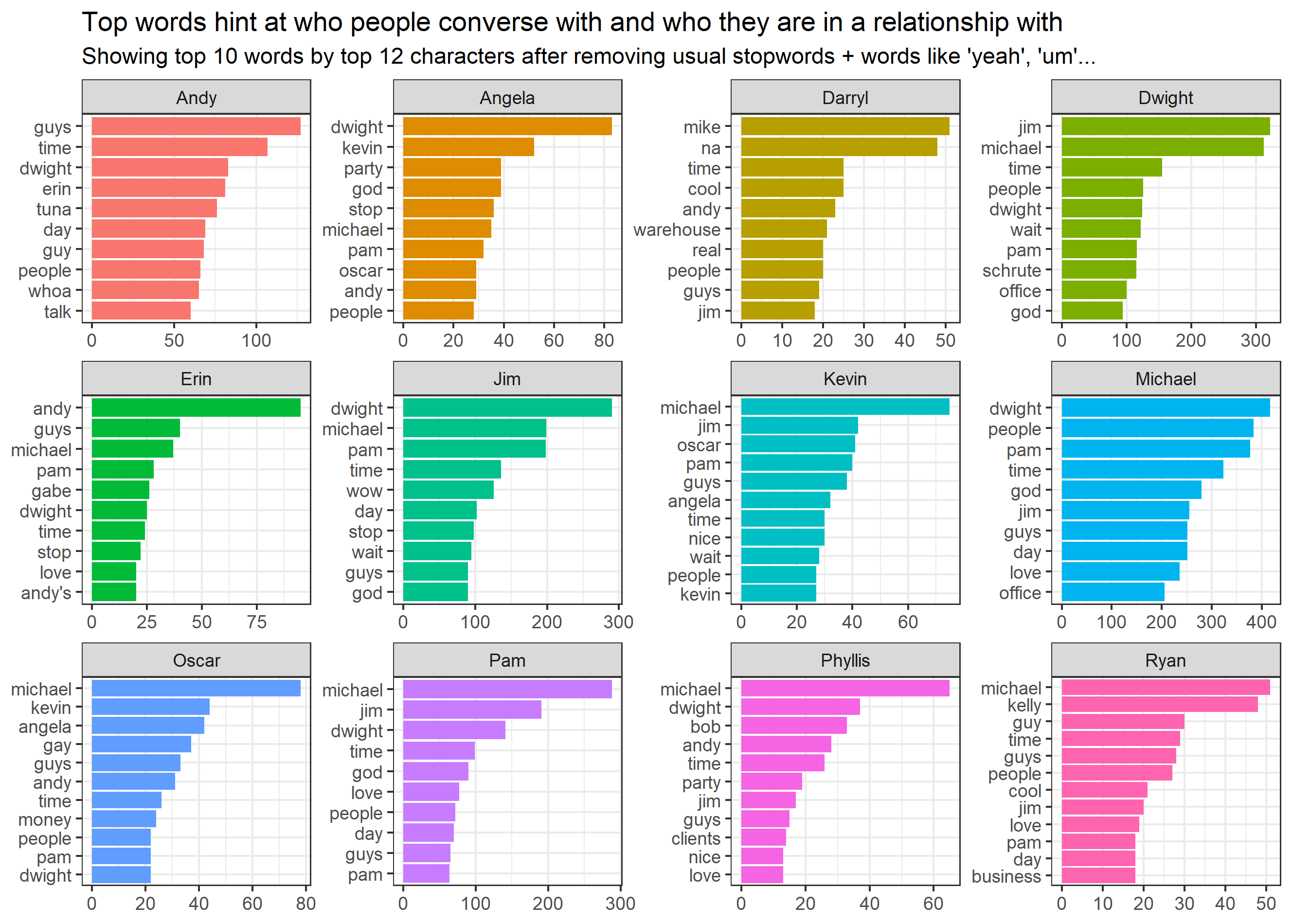
Elsőként tűnik fel, hogy a szereplők által leggyakrabban használt – jelentéssel is bíró – szavak, más szereplők nevei. Ez logikus, a sorozatban ugyanis egymással beszélnek, egymáshoz fordulnak a kollégák. Szintén előfordul, hogy a szereplők a saját keresztneveiket gyakran használják. Ez azért van, mert a legtöbbjük értékesítő, telefonon keresztül mindig bemutatkoznak.
Az egyes szereplőket a leggyakrabban használt szavak is megkülönböztetik (pl.: ’Tuna’ Andynél, ’Bob’ Phyllisnél vagy éppen ’warehouse’ Darrylnél), ám ennek ellenére, nem azonosítható be mindenki, sőt a legtöbb szereplőre nem ismernénk rá. Ezt egy szinttel javítja, ha szavak helyett szókapcsolatokat vizsgálunk. Ebben az esetben már kétszavas kapcsolatokat nézünk – melyeket ’bigram’-oknak hívnak, az általánosságban használt ’ngram’-ból fakadóan, ahol a ’gram’ jelentése „szó”, az ’n’ pedig a szavak számát jelöli –, szintén a ’stopwords’ jellegű szavak nélkül:
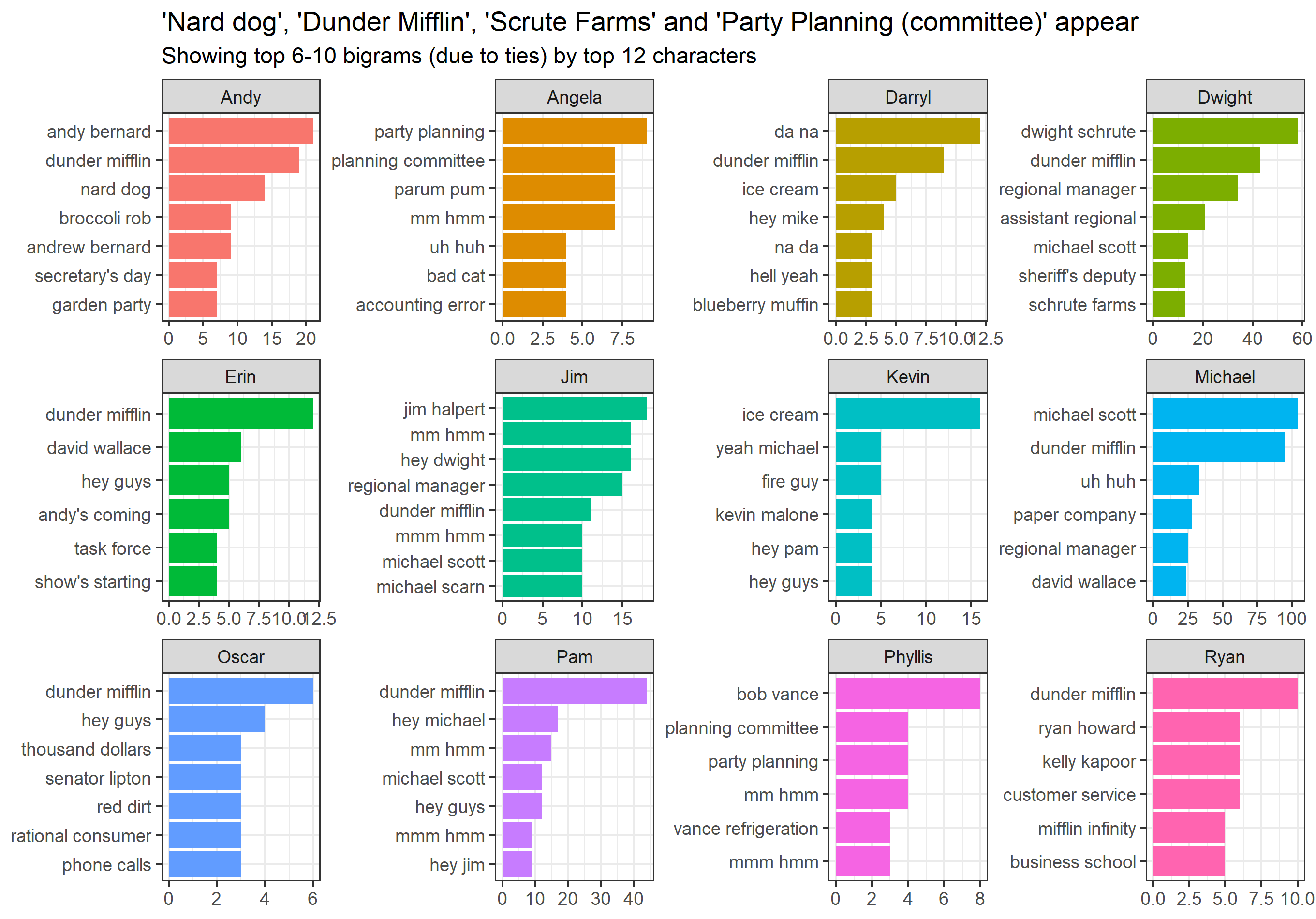
Ez a módszer már sokkal inkább használható arra, hogy letakarjuk a szereplők neveit, végig nézzük a szókapcsolatok listáit, és sikeresen azonosítsunk embereket a szókincsük alapján. Ilyen azonosításokra példa: Andy által használt ’Broccoli Rob’, Angelanál a ’party planning (committee)’, Dwight farmjának vagy éppen Phyllis férjének a neve, esetleg Oscartól hallott ’Senator Lipton’.
Csupán a szöveg szavakra való bontása, illetve információt nem hordozó szavak kivétele már segít a szereplők azonosításában. A tf-idf algoritmus ennél is pontosabb eredménnyel kecsegtet. A szavak egy szereplőnél, illetve szereplők közötti gyakoriságokkal számolva eljut addig, hogy minden szereplőhöz hozzárendelje a leginkább hozzá tartozó, leginkább csak általa használt szavakat. Tekintsük is meg, melyek az egyes szereplők legsajátosabb szavai.
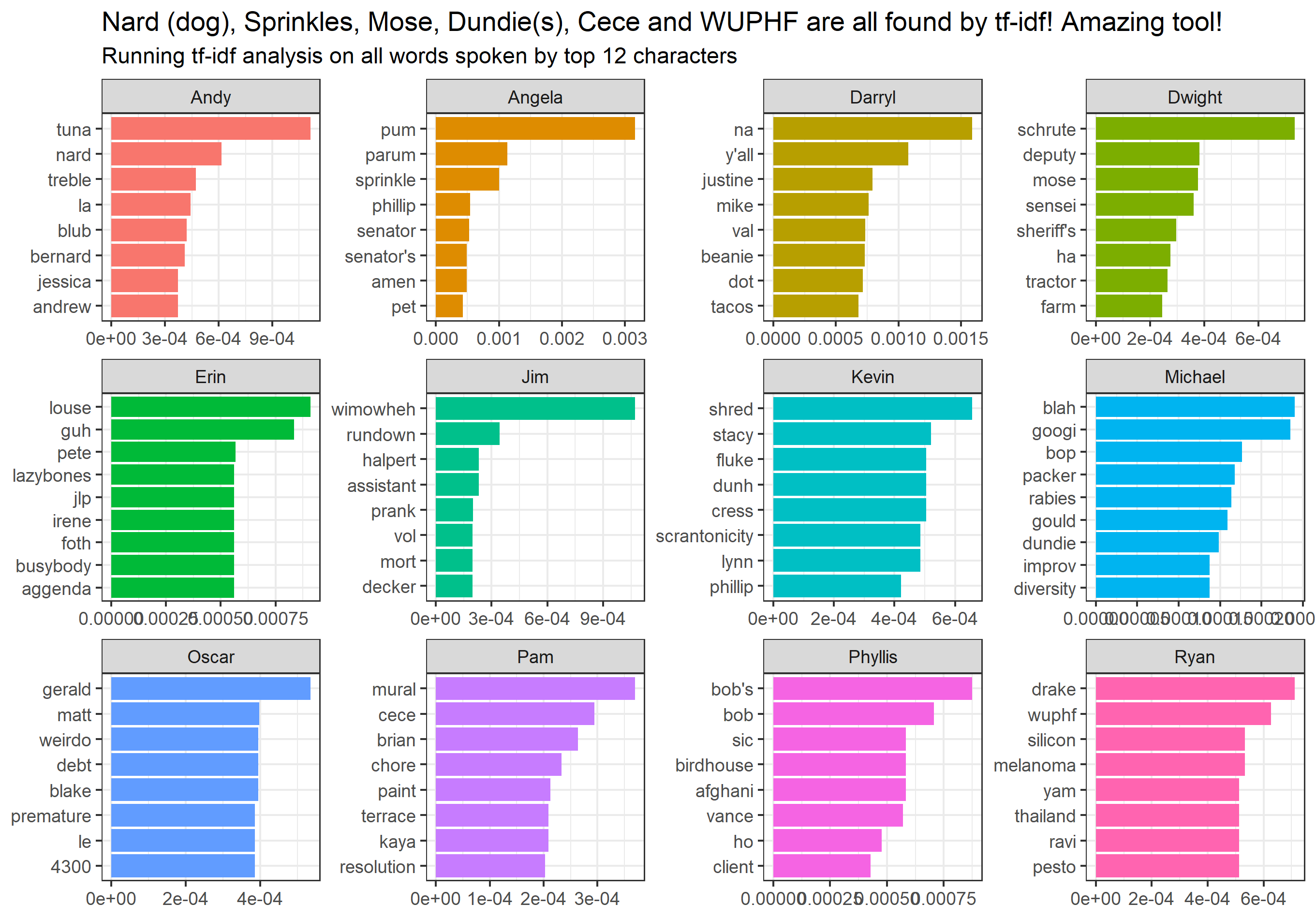
A sorozat kedvelőinek a fenti szólisták már mindent elmondanak. A szavakat végigolvasva biztosan megmondható, kihez tartoznak. Vessünk egy pillantást arra, miket talált az algoritmus: Andy-re: ’tuna’, ’treble’, ’Jessica’, Darryl-re: ’Justine’, ’Mike’, ’beanie’, Ryan: a nagyszerű találmány, a ’Wuphf’, Pam: ’Cece’ és ’mural’, hogy párat kiemeljek. Ha letakarnánk a neveket és a listák alapján kellene megtippelni, kiről van szó, az igazi The Office fanok biztosan sikerrel járnának! Ez az algoritmus a könnyen kezelhetősége és nagyszerű eredményei miatt az egyik legértékesebb eszköze a szövegelemzésnek.
Az eddigiekben a szereplők szókincsére fókuszáltunk, megnéztük a leggyakoribb szavakat és szókapcsolatokat, valamit a szereplők legsajátosabb szavait. A következő részben a szentiment-elemzésen lesz a hangsúly, valamint a hasonlóan kommunikáló szereplők megtalálásán.
Rábay Kristóf – Data Scientist