
Olvasási idő: 5 perc

Tartalomjegyzék
- Bevezetés
- Twitter scrapelése és Amazon Comprehend használata R-ben
- Szentiment elemzés
- Összegzés

Photo by Lidya Nada on Unsplash
Bevezetés
Az első cikkem a Mediumon egy egyetemi projekt részeként íródott. Szeretném kiemelni, hogy inkább technikai szempontból közelítem meg a témát, tehát nem az elemzést fogom hangsúlyozni. Inkább azt mutatnám meg, hogy miként állíthatunk fel egy framework-öt a szentiment elemzés egyszerű elvégzéséhez. Mindezek mellett, egy olyan esetbe nyújtanék betekintést, amelyre ezt a framework-öt alkalmaztam.
Képzeljük el, hogy egy neves angliai labdarúgó klub tulajdonosa vagyunk és meg akarjuk tudni, mit gondolnak a szurkolók a klub menedzseréről. Hogyan lehet ezt egyedül, költséghatékonyan és viszonylag gyorsan megtenni? Alapvető kódolási készséggel, egy Amazon Web Services fiókkal és kevesebb, mint 5 dollárral szép áttekintést kaphatunk a rajongók elégedettségi tendenciáiról a menedzser teljesítményét illetően. Vágjunk bele a tweetek szentiment elemzésébe! A cikkhez tartozó kódom itt található meg: github.
Twitter scrapelése
A twitter API használatához rendelkeznünk kell egy twitter fiókkal, a twitter alkalmazást itt lehet létrehozni. Körülbelül 40 percet vesz igénybe az alkalmazás beállítása, mert rengeteg űrlapot kell kitölteni, de amikor ezekkel végeztem, pár perc múlva meg is kaptam a visszaigazolást. Ez a cikk jó áttekintés ad arról, hogyan lehet ezt egyszerűen megcsinálni.
Ha mindezekkel elkészültünk, a dashboardon valami hasonló lesz látható (a biztonság érdekében kitakartam a kulcsokat és tokeneket):
Twitter Developer Dashboard
Az rtweet az egyik R package, amely használható a twitter API-hoz. Ezzel a kóddal twitter token generálható a hitelesítő adatok megadásával:
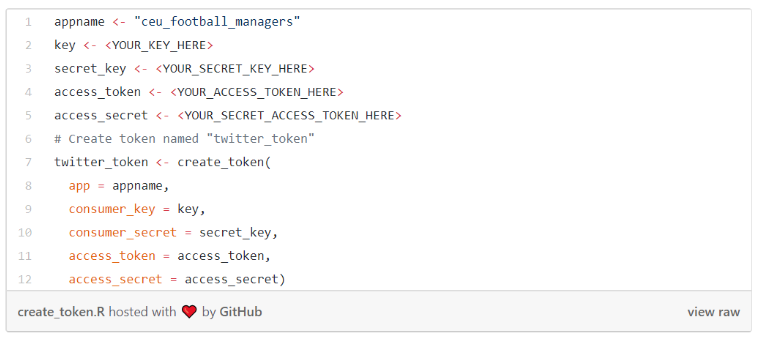
Create a token in rtweet: link.
Ezután már tudunk kommunikálni a twitterrel az R-ben. A következő lépés az Amazon Comprehend hozzáférésének beállítása. Ehhez természetesen szükség lesz egy AWS-fiókra, tehát, ha még nem rendelkezünk vele, akkor épp ideje van ezt létrehozni. Legfeljebb 10 percig tarthat ez a művelet. Ahhoz, hogy biztonságosan lehessen kommunikálni az API-val, egy hozzáférési kulcsot kell generálni az Amazon hozzáféréskezelő (IAM) konzolján. Mentsük el az R projekt helyére a kulcsot. A dashboardon valami hasonló lesz látható.
Amazon IAM dashboard
Az aws.comprehend R package-dzsel tudjuk használni a Comprehend servicet. Ahhoz, hogy használni tudjuk, először meg kell adni a hozzáférési kulcsot. Az alábbi kód mutatja meg, hogyan lehet ezt végrehajtani. Erről bővebb áttekintést ezen a github oldalon találhatunk.
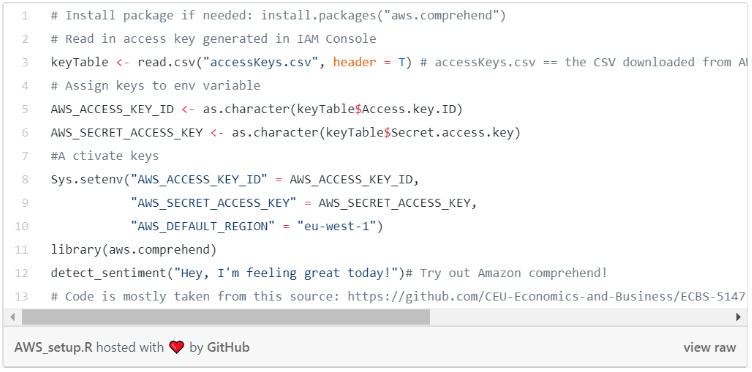
Set up Comprehend: link
Most hogy mindent beállítottunk, álljunk neki a football tweetek szentiment elemzéséhez!
A szentiment elemzés
A szentiment elemzéshez csak az angol tweeteket vizsgáltam, bár a cikk írásakor az Amazon Comprehend öt másik nyelvet is támogatott. Az elemezni kívánt tweetek mennyiségét földrajzilag csupán országos szintre akartam korlátozni, mert úgy gondoltam, hogy a rajongóknak nagyobb hatásuk van az anyaországukban lévő klubbokra. Kiderült számomra, hogy bár a twitter API bizonyos földrajzi adatokat szolgáltat, ezek erősen hiányosak. Így mégis inkább úgy döntöttem, hogy az összes angol nyelvű tweetet megtartom.
Muszáj felhívnom arra is a figyelmet, hogy a twitter némiképp korlátozza a tweetek lekérdezését. Jelenleg a támogatottan letölthető tweeteket 7 napra visszamenőleg szerezhetjük meg, ezért előre kell tervezni, ha egy adott jövőbeli esemény tweetjeit akarjuk elemezni, sőt, amennyiben valami váratlan történik, gyorsan kell cselekedni. A twitter tehát limitálja a lekéréseket, de erről egyéb pontosabb információt nem találtam. Mindenesetre nekem sikerült fél óra alatt 36000 tweetet lekérdezni, így nem tűnik nagyon korlátozónak a twitter API.
Az elemzésem tárgya Pep Guardiola, a Manchester City menedzsere. A City 3-1-re veszített 2019.11.10-én a Liverpool ellen, ezzel utóbbinak 8 pont előnyt biztosítva a Premier League-ben. Meg akartam tudni, hogy a football szurkolók hogyan reagálnak erre a zakóra. A mérkőzés 5 nappal az elemzés elvégzése előtt zajlott, tehát még épp időben voltam.
A tweetek lekérdezése és megtisztítása
Ahhoz, hogy leszedjük a tweeteket a twitter API-ból, egyszerűen használjuk az rtweet search_tweets() funkcióját. Az előálló object egy dataframe lesz 90 oszloppal, amely könnyen kezelhető és további változókkal bővíthető. Az rtweet dokumentációját böngészve tájékozódhatunk, hogy milyen egyéb attribútumok kérhetőek le egy tweethez.
A szöveges oszlopokba a felhasználók tweetjei kerültek. A tweetek általában URL-eket és hangulatjeleket tartalmaznak, ezek eltávolításával segíthetjük az Amazon Comprehend-et abban, hogy jobban kitalálja a tweetek hangulatait. Egyébként könnyen megeshet, hogy a tweetek szentimentjeit könnyebb meghatározni az emojik elemzésével, de arról nem találtam információt, hogy a Comprehend felhasznál-e hangulatjeleket az érzelmek észleléséhez. Biztos nagyon izgalmas lenne, ha készülne egy másik szentiment elemzés, amely csupán a hangulatjelekből készülne, majd azt összehasonlítanánk a Comprehend általi eredményekkel.
Tehát szabaduljunk meg ezektől a hangulatjelektől jelenlegi elemzésünkhöz. Megállapítottam, hogy az R base enc2native() függvénye tudja a legügyesebben UTF kódolásra konvertálni a tweeteket anélkül, hogy bármilyen egyéb információt elveszítenénk. Beillesztettem a kódrészlet legfontosabb részét, de a teljes kódot megtalálod a githubomon.
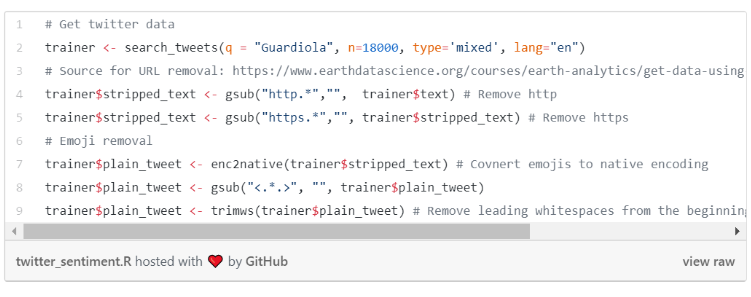
Egyébként az rtweet-nek van egy funkciója, plain_tweets(), ami hasonlóan tisztítja meg a tweeteket, de azt tapasztaltam, hogy az én módszereim hatékonyabban működnek.
Most, hogy végeztünk az adattisztítással, próbára is tehetjük az Amazon Comprehendet, de ezelőtt még jó lenne megbecsülni a várható költségeket. Az Amazon Comprehend kedvező árazású, de nem akarjuk, hogy valamilyen hiba miatt a tervezettnél többet kelljen fizetnünk. E célból létrehoztam egy olyan függvényt, amely megbecsüli a lekérdezés költségeit.
Az Amazon 0,0001 $-t számít fel karakterenként és legalább 0,0003 $-t kérésenként (ez azt jelenti, hogy ugyanannyit fizetünk 100 és 300 karakternyi tweetért is). Az én adatbázisom 17997 megfigyelést tartalmaz, az egész adathalmazt tekintve becsléseim szerint ez 5,2 $ értékű lekérdezést fog eredményezni.
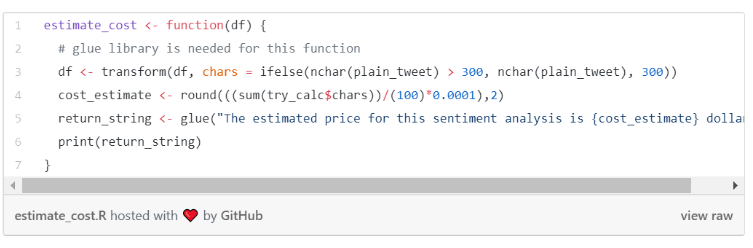
Érdemes megemlíteni, hogy bár az Amazon Comprehend nem tűnik drága megoldásnak, de azért mégsem a tweetekre találták ki. A tweetek – a hangulatjelek és URL-ek eltávolítása után – már jóval kevesebb karaktert tartalmaznak, mint 300. Ennek szemléltetésére készítettem egy karaktereloszlási diagramot a tweetek karakterhosszáról.
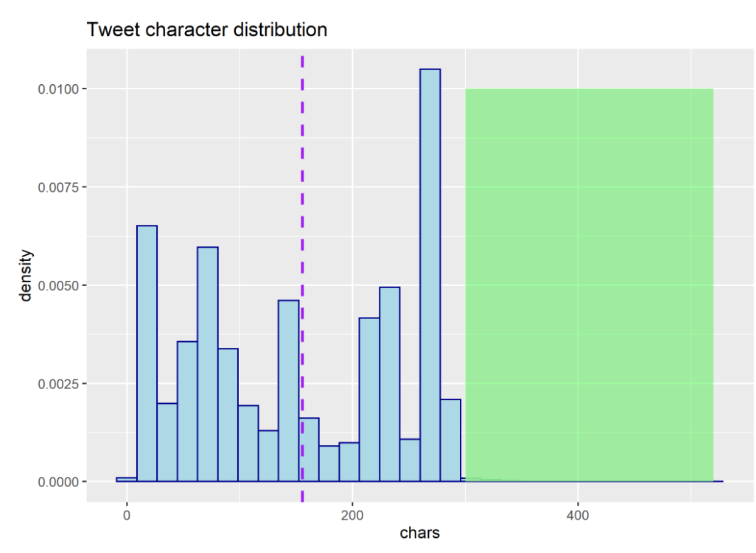
Egy tweet átlagos hossza 157 karakter, 0,3%-uknál több, mint 300 karakter, de körülbelül 24%-uknál hosszabb, mint 250 karakter. Aggódhatunk amiatt, hogy ez a karakterszám vajon elegendő-e a hangulatok kifejezéséhez? Annak érdekében, hogy tudjuk, mennyi is a 157 karakter, bemásoltam egy ekkora hosszúságú tweetet:
“@<blurred_user> is a very good manager, no doubt, but he always had best team at his disposal. Klopp has made average teams become excellent teams.”
Én úgy érzem, hogy nem feltétlenül van szükségünk hosszabb tweetekre, hiszen lehet, hogy még a rövidebbek is, mint például: “Booo Guardiola” vagy “GTF Guardiola” is jól megállapíthatóan inkább negatívak vagy pozitívak, mintsem semlegesek lesznek. Egyébként nem vagyok nagy szakértője az NLP-nek, csupán némi kontextust szerettem volna adni az elemzésnek.
Tehát, bár pénzügyi szempontból nem feltétlen érdemes rövidebb szövegek szentimentjeit lekérdezni a Comprehend-ből, ettől még juthatunk értelmes eredményekre.
Szentiment elemzés
Az Amazon Comprehend használatakor kapunk egy valószínűségi pontszámot a négy érzelemhez (vegyes, negatív, semleges, pozitív) a legvalószínűbbnek találtat a ’Sentiment’ oszlopban láthatjuk. Ezt szem előtt tartva meghatározhatunk egy olyan függvényt, amely extraktálja a tweet oszlopot, majd ezt a szöveget elküldi az Amazon-nak, és vízszintesen csatolja a visszaadott adatkeretet a ’base’-hez.
Ezzel megvan a dataframe tweetekkel és a hozzájuk tartozó szentimentekkel. Ideje megnézni, hogy az emberek mit gondolnak Pep Guardiola-ról, miután a csapata elvesztette a nagy rangadót.
Ehhez először vessünk egy pillantást az adatkészlet dátumtartományára. Azt láthatjuk, hogy a tweetek 2019.11.12-től 2019.11.15-ig (a cikk írásának ideje) terjedő napokra esnek. Ez kevéssé szerencsés, mert reméltem, hogy lesznek tweetjeim a játék napjáról is (10.11.), mivel arra számítottam, hogy a rajongók hevesebbek lesznek a pillanat hevében, majd fokozatosan megértőbbé válnak. Csak az elemzés elvégzése után lett számomra világos, hogy amikor meghívjuk a twitter API-t, akkor az ‘until’ argumentummal megadhatjuk, hogy csak egy adott nap előtti cikkeket kerjen lel. Erről további információt itt találhatunk.
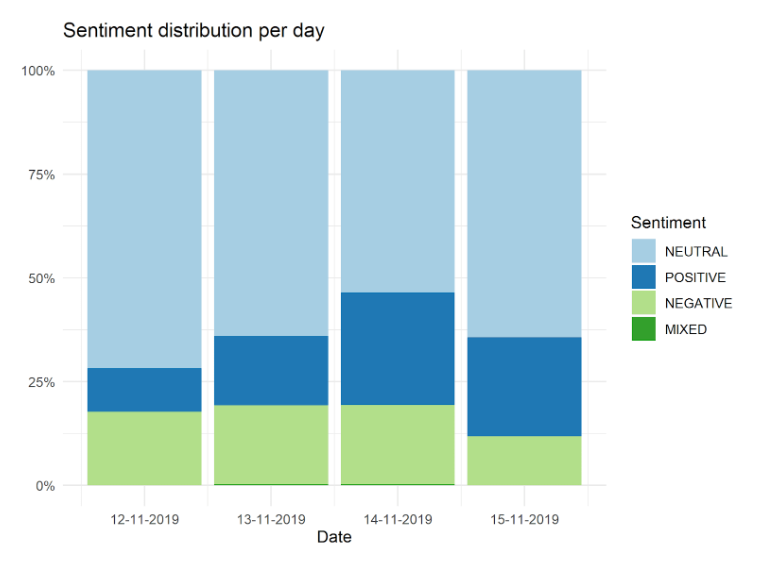
Mindenesetre, ahogy már az elején utaltam rá, ez a cikk csupán a keret bemutatására irányul, melynek nem feltétele a módszertanilag hibamentes elemzés. Ezt fejben tartva, nézzük meg a tweet szentimentek relatív gyakoriságát. Mint láthatjuk, a semleges érzelmek dominálnak 57%-kal, a pozitív érzelmekhez tartozó érték 23%, a negatívokhoz pedig 18%. A kevert érzelmekkel rendelkező tweetek alacsony gyakoriságuk miatt figyelmen kívül hagyhatóak.
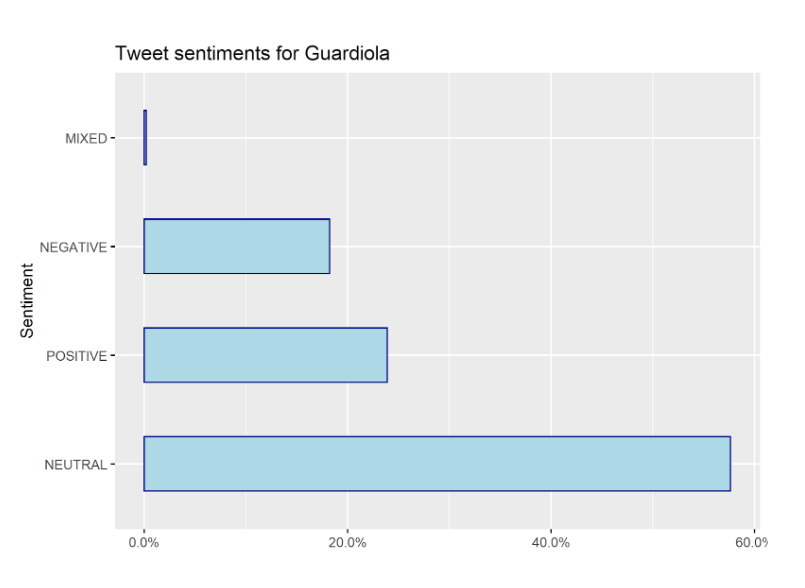
Érdemes megnézni, hogy a tweet szentimentek hogyan alakulnak a játék után. Az alábbi ábra azt mutatja, hogy a meccs után a semleges érzelmek csökkennek, amelyet a pozitív érzelmek növekedése okoz, míg a negatívok nem sokat változnak. Tehát valószínűnek tartom, hogy a rajongók egyre inkább megértővé válnak egy nagy játék elvesztése után, ez az oka annak, hogy növekszik a pozitív tweetek aránya a negatívokkal szemben.
Összegzés
Ebben a cikkben bemutattam, hogy az Amazon Comprehend hogyan használható R-ben tweet szentimentek detektálására. Nagyon könnyű ezt a frameworköt beállítani, és ezen módszer alkalmazásával egyszerűen elemezhető, hogy az emberek mit gondolnak egy adott eseményről. Mindezt idő-és költséghatékony megoldásnak gondolom, azonban továbbra is felmerül a kérdés, vajon az Amazon Comprehend elég jól működik-e céljaink számára. A közeljövőben azt tervezem, hogy összehasonlítom az Amazon Comprehend szentiment előrejelzéseit hangulatjelekkel és megnézem, hogy ezek mennyiben térnek el egymástól.