
Reading time: 6 min

In Part I., we argued in favor of using Superset as a free and open-source solution. Make sure to check it out beforehand to understand our dedication and excitement towards the project.
Now, let’s dig into how we have test-driven Superset on top of other fascinating technologies.
Setup
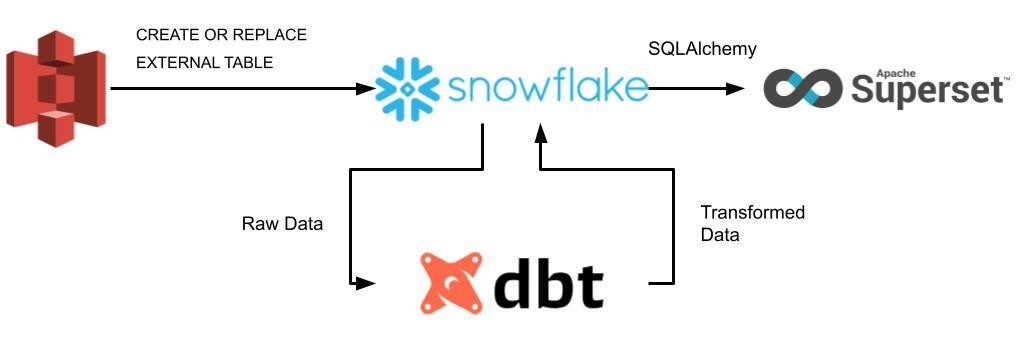
How we set up our infrastructure
We set out to showcase how Superset can consume data from a centralized data store such as Snowflake and build a stack of promising technologies.
- For that purpose, we leveraged the generated TPC-DS sample data as described in the specification on our S3 bucket and set it as a named external stage on our Snowflake.
- After that, we transformed the raw data with dbt models and tests within dbt Cloud before loading it back to Snowflake via the dbt run command, thereby creating a data mart.
- To finish our continuous pipeline, we established the connection between Snowflake and Superset and assembled an example dashboard of the data mart.
The data mart of promotions followed a star schema approach, where the fact table consisted of approximately 5 million rows and 47 columns. Moreover, we also set up a modern-analytical wide table by flattening the star schema into one joined table to test the performance of Superset.
Why use dbt for the T in ELT?
dbt can be considered as a perfect companion to Snowflake for data transformation:
- dbt is a “more for less” solution as it is faster and cheaper than its predecessors
- Well-integrated with Snowflake
- Models are written in the mix of SQL and JINJA templating which is friendly for non-data engineers, while makes it quite expressive and fairly easy for data engineers
- Rich templating allows you to seamlessly write macros for your models and parametrize your environment
- Template-based SQL is a good combination with Snowflake’s warehouse auto-scaling, zero-copy clonings, streams, and support for semi-structured data features
- It’s heavily oriented towards collaboration, sharing, and reusability
- The option for testing is handy when it comes to ensuring the data quality and avoiding the error proneness
Findings
Our assessment is manifested in various findings.
- After installing the appropriate drivers it was pretty straightforward to connect our Snowflake database with Superset, as again, the connection string was made in accordance with the SQLAlchemy engine syntax.
- Having the dataset available within Superset, we could quickly create a dashboard with multiple charts which can offer credible answers for our promotions data inquiries and exhibit how it can be used for ad-hoc analysis.
- To our experience, assembling the charts and dashboard was as clear as possible: Superset makes it easy by guiding you through the necessary parameters.
- Unlike in other leading commercial platforms, the UI isn’t cluttered with many features and is easy on the eye given its simplicity. Put differently, it gets the job done in style and efficiency.
Let us now evaluate the layers of Superset!
SQL Lab:
- In parallel to the simplicity and clarity of this tool, it has everything needed by default for ad-hoc data wrangling, while the feature set can be extended based on the needs.
- Queries run smoothly without any disruption, and the IDE is intuitive enough to be used at any level.
Data Exploration:
- Independently from using a virtual or real table, shuffling between visualization types has never been more satisfying, especially considering the project’s maturity.
- Also provides the possibility to shift between granularities at ease and either create new metrics or restructure the dataset.
- Although we only used the default visualization plugins, creating custom apps and visualizations are relatively straightforward thanks to Superset’s architecture and the designated documentation.
Dashboarding:
- Assembling a chart works as one would expect as we can drag and drop our charts onto the dashboards and scale them with the help of grid lines.
- The CSS of the dashboard can be easily tailored to your tastes, and the default components allow us to beautify visualizations even with Markdown.
- After publishing the dashboards, one can (bulk) export them manually as JSON files from the interface, and import them to any Superset instance given that it has access to the source database.
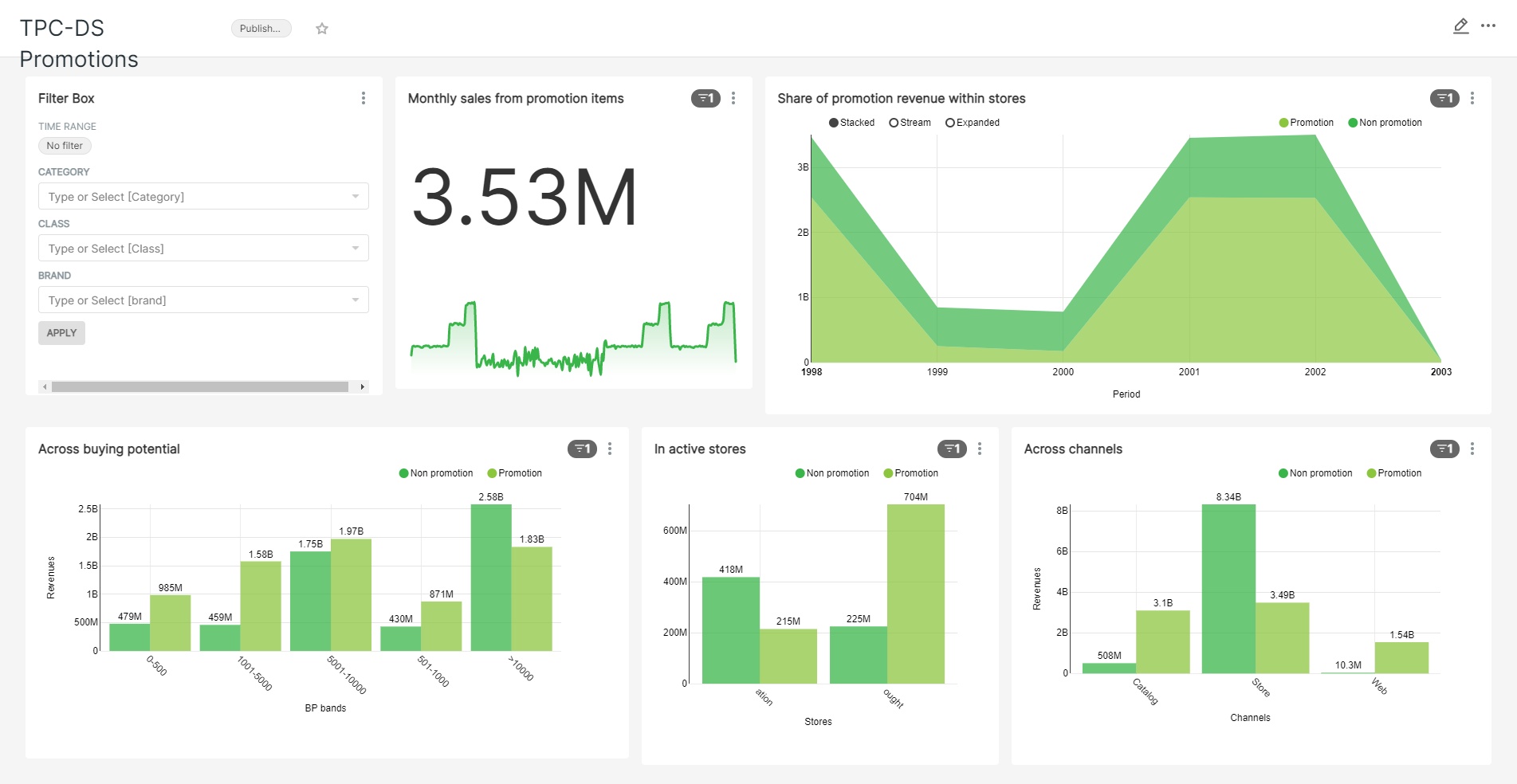
A snapshot of how we set up our dashboard
Further remarks
Firstly, according to the official documentation, Superset isn’t officially supported on Windows. Thus, Windows users can only try out superset locally via an Ubuntu Desktop VM or using WSL(2). The former likely works, but it wasn’t efficient from our standpoint. Even though we iterated through the latter option, unfortunately, we bumped into unknown or known- but-unresolved issues. We eventually managed to initiate Superset locally by starting the DockerHub image step-by-step (instead of docker-compose), but we suggest you avoid installing it on Windows if you can. That being said, we hope that sooner or later, it will be natively supported. It’s also important to highlight as a footnote that we self-hosted the 0.999.0dev version of Superset throughout our testing.
Secondly, it’s advisable to index (or cluster) the source tables (or materialized views) of visualizations, optimize both vertically and horizontally the underlying virtual warehouse in Snowflake as well as performing a micro-partition pruning (or dimensionality reduction). Otherwise, slices and dashboard queries tend to timeout due to concurrency, especially if filters are applied to multiple slices on the dashboard. This can be verified by investigating the execution plan of each chart within Snowflake’s query profile section and checking whether TABLE SCANNING consumes the lion’s share of the resources. Since queries can be saved and also tracked back within Superset, we can always reuse previous queries. Note, that our top priority wasn’t to benchmark the query performance of Superset within Snowflake, although we gained a general sense of it during our work.
Thirdly, Superset stores the dashboard components (metadata, and slice configurations) within its dedicated database, thus, we decided to manually store and transfer dashboards between instances rather than mounting the database onto a host folder and glue together each particle of a dashboard. Just to refer back to what has been said in Part I., the Superset community is very close to a pull workflow solution where you can play with YAML files of dashboards through the API. To our understanding, Superset supports exporting individual dashboards with a CLI command, but as of now we also feel the urge to also develop a bulk export option.
Conclusion
Let us not quickly summarize what we have learned together!
Commercial BI tools have been ruling the market for years until cost-friendly open source candidates started to show up gradually. Among those, Superset is considered one of the most exciting projects, and it’s certainly worthy of keeping an eye on.
We exposed Superset to a stack of auspicious technologies, notably dbt which is also an important technology Hiflylabs is moving forward with. From our experience, the learning curve is shallower compared to the feature-loaded counterparts, whereas we mustn’t skip past the beauty and simplicity of Superset’s visualizations. We are committed to both the dbt and Superset open-source projects and we look forward to extending our client base by offering services on both in the foreseeable future.
As there have been instances for Superset slowly overtaking costly BI tools, we also hope to contribute to the initiative to cut costs and leverage our expertise in supercharging Superset. Even though there are downsides of using Superset due to its recent graduation, we believe that the strong community and the committers behind the project can launch the product into highs matching its potential.
Now that you have seen Apache Superset synthetizing with products such as Snowflake and dbt, what are your impressions on it being the “chosen one” among the free and open-source solutions? Do you see any possibility of Superset establishing its noticeable share in the overheated data visualization market? Let us know in the comment section below!
Author:
Son N. Nguyen – Data Engineer