
Reading time: 7 min

This article is part of the short series. Part I. deals with demonstrating the strengths of Superset and how it’s situated in the diverse dataviz market, while the upcoming Part II. will discuss our experience in implementing and testing Superset on the pipeline illustrated with the figure below.
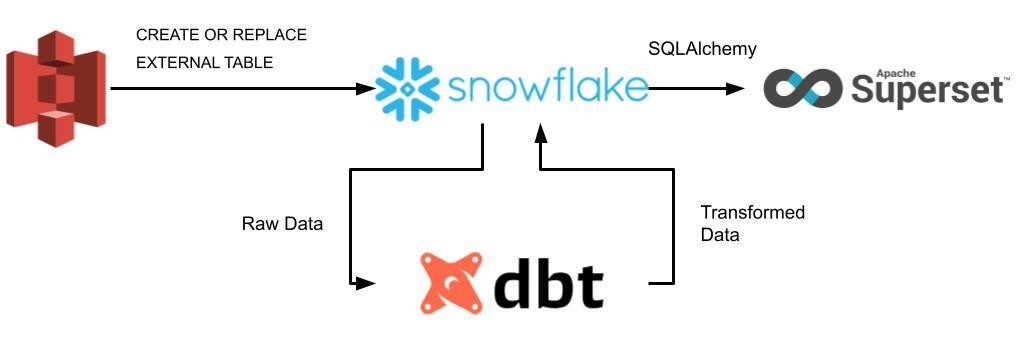
How we set up our infrastructure
Introduction
When we talk about interactive data visualization, especially in the context of modern data stacks (e.g. data streamer (Stitch, Fivetran, Airbyte) + centralized cloud storage (AWS, Azure, GCP, Snowflake, Databricks) + transformation tool (dbt) + BI platforms), proprietary tools pop into our head such as Tableau, Power BI, and more recently Looker. These were considered as the mainstream solutions for quite a while, but now, emerging open-source alternatives are hungry enough to beat the market with their simplicity and cost-friendly approach. Among these promising technologies, Apache Superset is set to challenge its competitors in many ways, therefore, Hiflylabs closely monitors the roadmap of the project.
Given the maturity and dynamism of the BI market, consolidations are more frequent than ever. Over the past few years, other commercial tools were acquired by companies such as Tableau by Salesforce, Looker by Google Cloud, or Periscope by Sisense, which can infer the risk of vendor lock-ins forcing customers to migrate and rebuild their assets (e.g. Chart.io was downsized and shut down by Atlassian). Conversely, open-source platforms such as Superset avoid vendor lock-ins since you can both switch between commercial open source (COSS) vendors, and host it yourself on-premise. A good example for the former would be Preset (founded by the creator of Superset, Max Beauchemin), who offers a hassle-free and fully-managed cloud SaaS service to the platform.
So why is it relevant just now?
Well, as the name indicates, Superset started in the Apache incubator back in 2016 and quickly became one of its top priority projects coinciding with the recent stable release at the beginning of 2021. It’s a modern, lightweight, cloud-native, free, and open-source BI web application with an advantageous SQLAlchemy python backend, making it scalable and compatible with almost any database technology speaking SQL. To reflect its increasing popularity, Airbnb, Twitter, Netflix, Amex, and many other companies have already started incubating Superset in their workflows, while Dropbox managed to successfully exploit its advantages at an enterprise level. In addition, the growing community behind Superset further strengthens the argument that there is an undeniable potential in our sight.
Superset essentially stands on three main layers:
- Dashboarding:
- Seamless interaction with a wide range of tooltips
- Drag and Drop crafting
- Multiple ways of sharing your dashboard/charts (JSON, email, URL)
- Data Exploration (Slice & Dice):
- Code-free visualization builder to extract and present datasets
- Intuitive interface
- Apply dozens of preset and custom visualization plugins instantly
- User-defined metrics with scalable semantic layering
- Lets you view the SQL statement for each visualization
- SQL Lab:
- A feature-rich SQL IDE written in React
- A multi-tab environment lets you work on multiple queries at once
- Metadata browsing of tables, columns, indexes, and partitions
- Supports long-running queries by persisting query results and dispatching handlers to workers (Celery)
- Equipped with interactive querying, autocomplete, scheduling, query history, user-defined parameters (with JINJA templating through dbt CLI and dbt Cloud), etc.
How does it perform on the big stage?
- Given that it’s a web-based stack application unlike Tableau and Power BI, it was tailored for the consumption layer as the data isn’t stored on the platform. Hence, the heavy-lifting is rather done in the connected database, making it again more scalable than its competitors when it comes to an ad-hoc analysis.
- Given its cloud-nativeness, we can choose between standards and abstractions of web servers, metadata engines, and caching strategies. Also, it’s possible (and not even difficult) to change Superset SaaS providers or move the system fully in-house.
- We can’t emphasize enough how semantic layering contributes to the reusability of queries and the scalability of Superset.
- The high level of customizability is also appealing for us developers in the company. We didn’t even discuss the security features, which in essence gives us control over custom granularity roles and row-level security filters while supporting multiple authentication options and cache strategies. Speaking of the latter, along with the metadata and chart caching, the architecture allows us to set an additional asynchronous query caching mechanism to avoid timeouts during long queries.
- Other prominent features embrace the public REST API, the real-time compatibility (also with other Apache graduates such as Airflow and Druid), the ecosystem of custom visualization plugins, mail, and Slack alert support, streamline data access, cross-team sharing and the list goes on.
Head-to-head with Looker
We have seen many instances for pairing Looker with dbt, but the following arguments made us advocate for Superset:
- In contrast with Looker’s LookML, the learning curve of Superset is shallower thanks to its SQL-centric design being more approachable for the majority
- Looker only supports about 15 different types of charts with standard customizations, and due to its closed-source model, the ecosystem of custom visualizations falls short compared to that of Superset.
- Since Looker’s persistent derived tables (PDT) had their weaknesses in incremental rebuilds, the best practice was to either perform the data preparation at a database level or complement it with dbt. They have recently addressed the shortcomings, but it’s hard to imagine one leaving dbt and going back to PDT. Consequently, PDT is no longer a selling point for Looker, and it’s more reasonable to consider Superset as an alternative.
- Lastly, although Looker is comparable with Superset due to its web application nature, it has an enterprise pricing structure similar to commercial tools, while Superset is entirely free.
Why use Superset? – the case study of Dropbox
Let’s see a case study on how Superset was chosen to be implemented into enterprise-level production!
The table below was retrieved from a Dropbox article on Jan 19, 2021. Long story short, they desired to find one particular BI tool to replace multiple other solutions. The main emphasis was on the security, user-friendliness, maintainability, flexibility, and extensibility of the platform. Their choice also landed on Superset as it was the best match for their specific internal needs. As a part of their decision-making process, they provided a comparison table that shows that Superset is superior compared to its peers in terms of the number of features and compatibility.
Data Visualization Platform Comparison Matrix
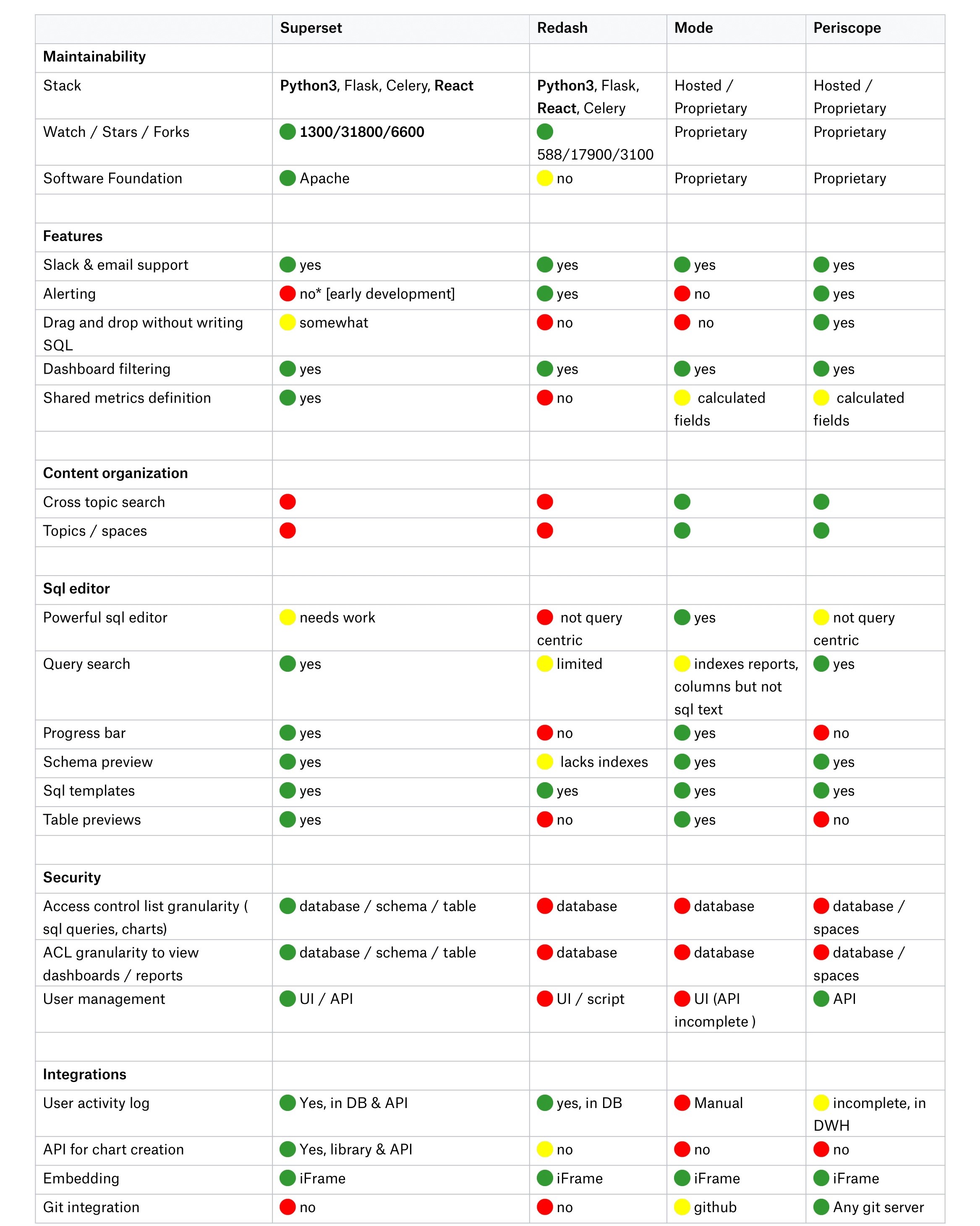
Source: Dropbox Tech – Why we chose Apache Superset as our data exploration platform
Dropbox explained ditching Metabase with the argument that it’s developed in Clojure rather than Python, while to their knowledge, it has shortcomings from many additional aspects compared to Superset, for example, it has less authentication and data backend support. Since Dropbox has many strong Python developers, they decided to pursue Superset instead of Metabase.
Limitations
Just as other tools, Superset also has its limitations.
- It doesn’t allow creating visualization from multiple tables within its Data Exploration layer. Simply put, tables have to be joined beforehand either at a database level or in the SQL Lab as a virtual table. We wouldn’t consider that as a missing feature but it can undoubtedly be inconvenient. However, it has generally been distilled as a best practice to prepare joins at the database level as much as possible (e.g. Looker’s LookML can do these joins but it has been found time and again that it shouldn’t be used for more than for quick prototypes.).
- As long as SQL is needed to manipulate tables before applying visualization, a basic knowledge of SQL can be beneficial but not considered a necessity.
- Being self-hosted is a double-edged sword: a blessing for flexibility but needs somewhat more effort on the maintenance side. We have found its maintenance needs well tolerable but it sure prompts for a Python web developer to be around.
- Cross-filtering between charts isn’t fully supported at the moment, but such should be available at any time now.
- Although it has extensive connection support, it doesn’t support NoSQL data sources.
- Version control isn’t an explicit feature as Superset stores the components of a dashboard separately in its dedicated database. That being said, Preset teased an upcoming feature allowing users to version dashboards as YAML configurations and move between instances through the API. In Part II., we will also mention alternative ways to transfer dashboards between Superset instances.
Did Superset spark some interest in you or it still falls short of being a credible solution to your pipeline? What are the missing features which would elevate the product to a day-to-day alternative for you? Make sure that your voice is heard in the comment section below! Also, stay tuned for the second part of the series!
Author:
Son N. Nguyen – Data Engineer