
Reading time: 4 min

My more technically rich writing in English can be read on Towards Data Science on the subject.
Introduction
Text mining and NLP include such tools that allowed Amazon to quickly determine of thousands of reviews, whether a product is liked by the customers or not, or let Twitter identify fake news by checking word usage, context and sentence structures. I’m going to try and demonstrate the power of text mining algorithms by running text analysis on a well-known TV series. The good news is that the techniques presented here are well within reach for smaller organizations to solve their text analysis related business problems.
To anyone who is quite familiar with the American The Office series, words or phrases like ‘dundies’, ‘Big Tuna’ and ‘wuphf’ mean something right away. Moreover, we even know who to associate the words with. It’s also common among The Office fans to know that Jim and Pam have a fairytale-like positive relationship (most of the time), or that Angela is quite the meanie. But can data science prove these hypotheses / facts, that we, the viewers know from watching the show?
In our two-part blog series we’ll leverage text mining methods to extract word and phrase usages by characters of the series, show their most personal words, outline their overall sentiments and sentiments between each other, and try to find people with similar vocabularies. In this first part we’ll be focusing on word and phrase usages, while in the second part we’ll show results from sentiment and topic (vocabulary) analysis.
As we take our readers through a nostalgic The Office journey, we hope to successfully showcase how powerful tools NLP offers, and how they can be used to find words by which characters of the show can easily and correctly be identified, or how they can represent relationships between people by analyzing sentiments between them.
For those who are wondering about technical aspects of the analysis: we used R and its following packages: (1) tidyverse and data.table for data manipulation, (2) tidytext, stringr, textdata, textstem, stopwords, sentimentr and topicmodels for NLP related work and (3) ggplot, igraph and visnetwork for visualizations.
Choosing the most talkative characters
Before jumping into analysis, Office fans know the series has its ‘main characters’, however the during its 9 seasons the show accumulated quite the number of roles. To make the results more comprehensible and easier to communicate, we selected a limited amount of characters, based on their line counts. The top 12 people with most lines cover around 80% of all lines – we’ll stick to them, following the Pareto principle. Let’s see who we’ll be working with.
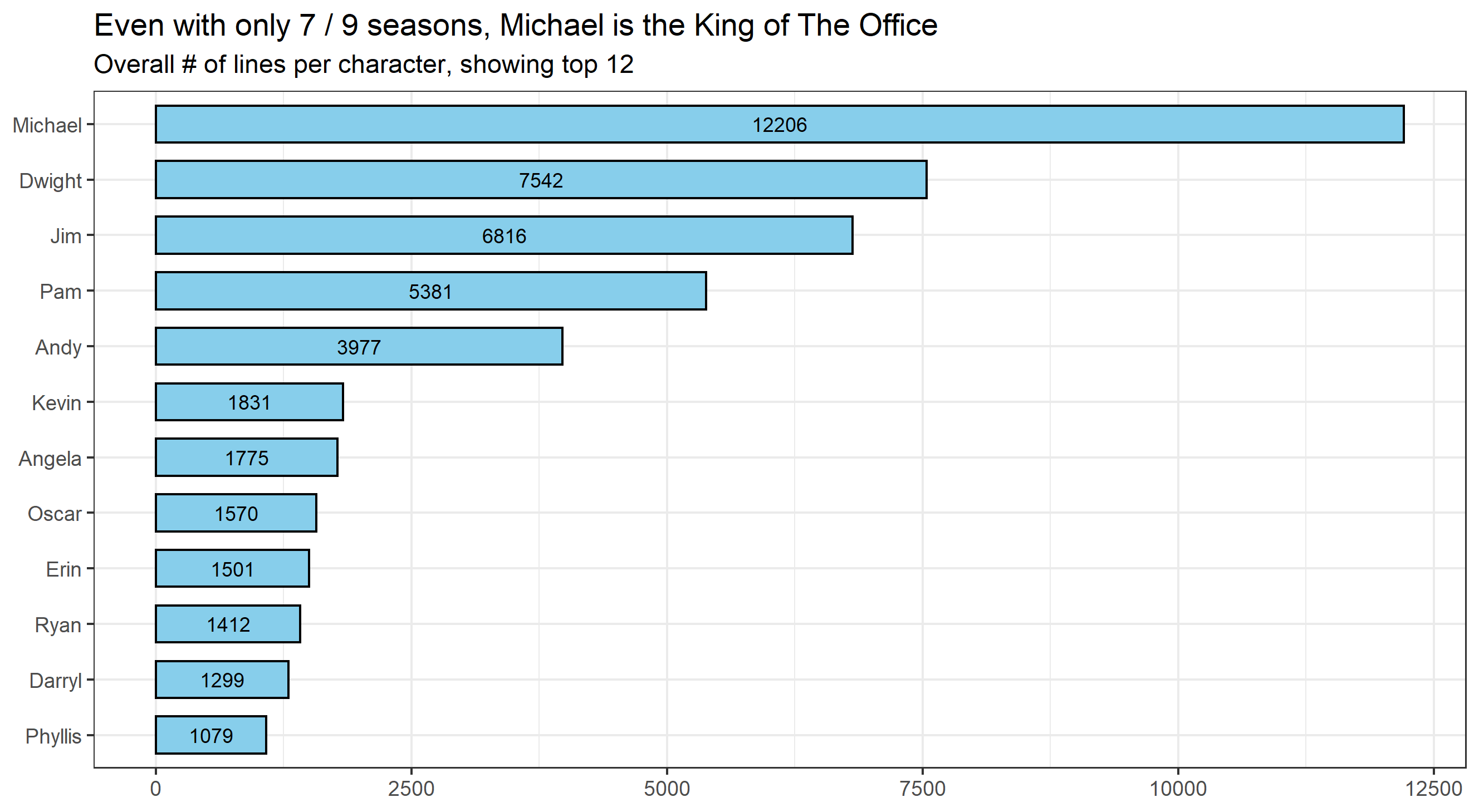
The above-mentioned people and their lines will be used for further analysis. It’s obvious Michael had the most lines throughout the whole series, despite not being part of the last two seasons. We can take a look at line count by season, to see who ‘took over’ Michael’s role for season #8 and #9.
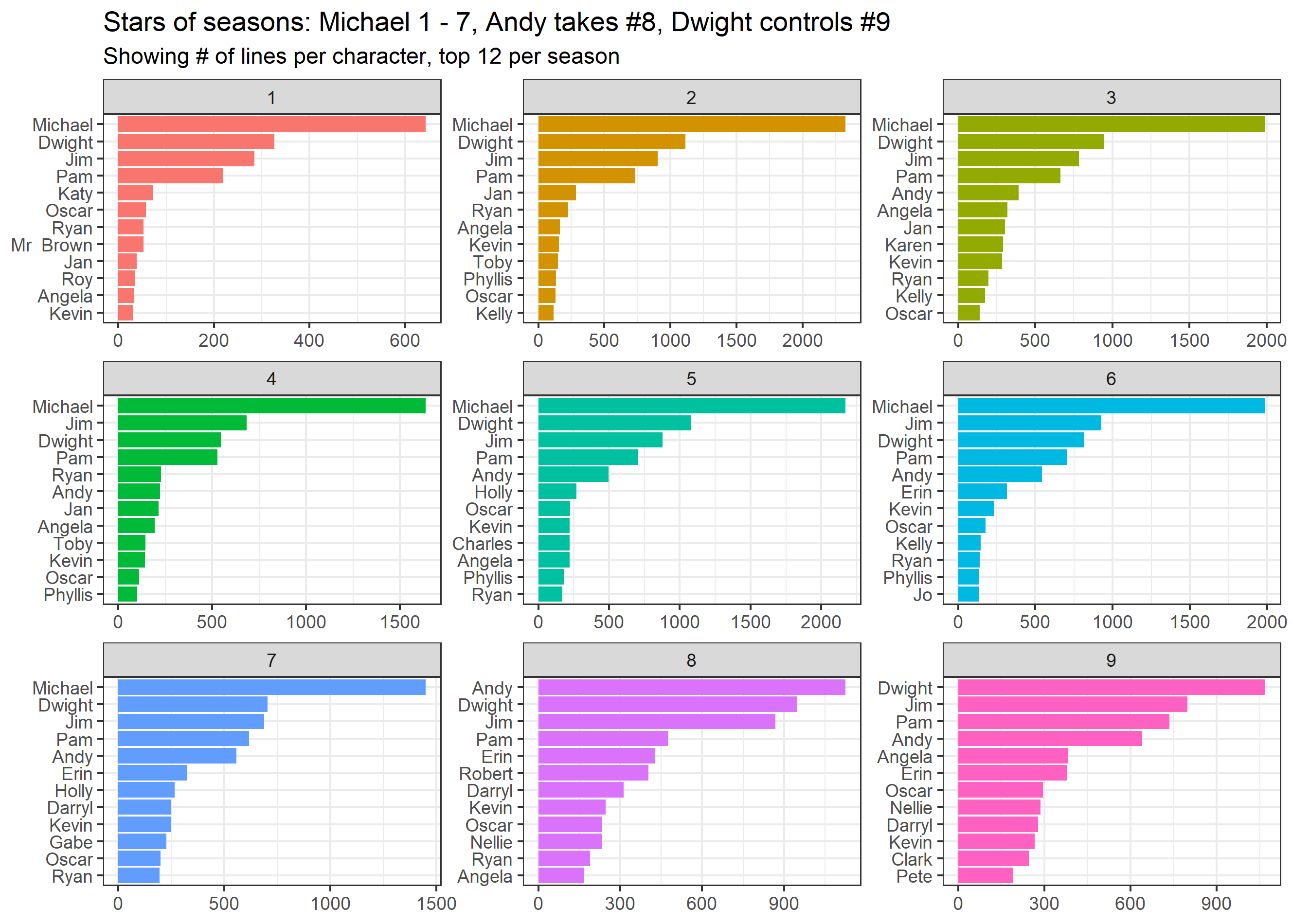
Andy, Dwight, and Jim had larger roles in the final seasons due to Michael’s departure, although neither of them had such a large weight as Michael used to have up until season #7.
Most frequently used words and phrases, most unique-to-person words
In order to familiarize ourselves with the top characters’ vocabularies, we first take a look at their most frequently used words. We call breaking down the lines, sentences to word levels tokenizing. It’s important to note that the below lists will be lacking words like ‘me, you, the, and’, etc… That’s because these words carry neither information nor sentiment, they’re called stopwords and have grammatical role to make speaking more fluent. After removing these stopwords, here are the terms the top characters use.
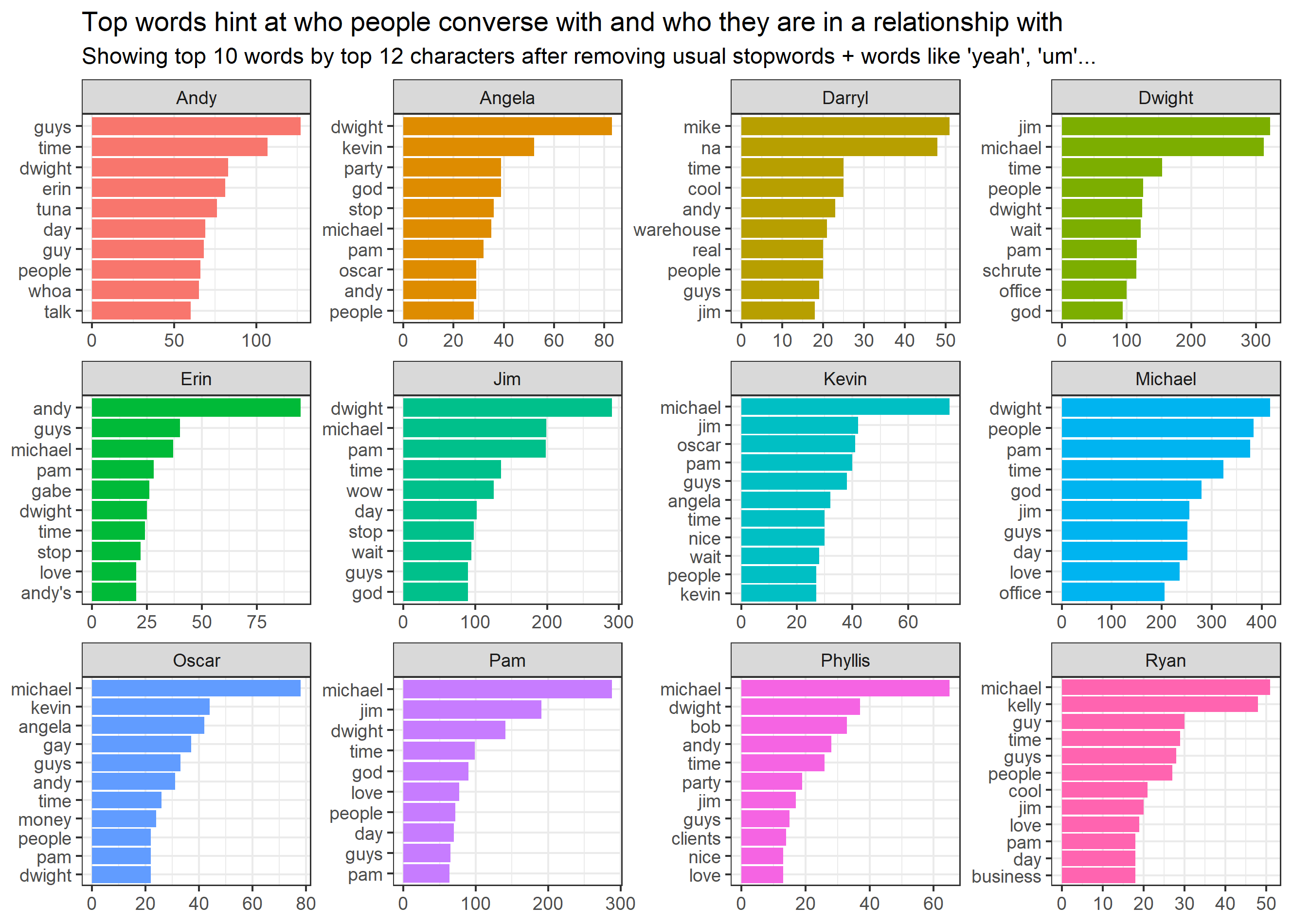
An interesting first insight is that the most frequent words – that carry some sort of meaning – are names of other characters. This makes sense as colleagues, when turning to each other, always call each other by their names first. Other than that, the lists also include people’s own names. This is also logical, as the series focuses on a paper company and mostly its salesmen (and one receptionist) who always need to introduce themselves over the phone.
By looking at the most common words, it’s quite difficult to identify people – although not impossible: Andy’s ’Tuna’, Phyllis’ ’Bob’ or Darryl’s ’warehouse’. Identification chances can largely be improved by looking at most common phrases instead of just words. We’ll be looking at two-word phrases. They’re called bigrams – a specific form of ngrams, where ‘grams’ simply mean words, ‘n’ stands for the number of words looked at at the same time – in this case 2. We’ll also be focusing on phrases that have some meaning, so we’ll be using bigrams where neither the first nor the second word is a stopword.
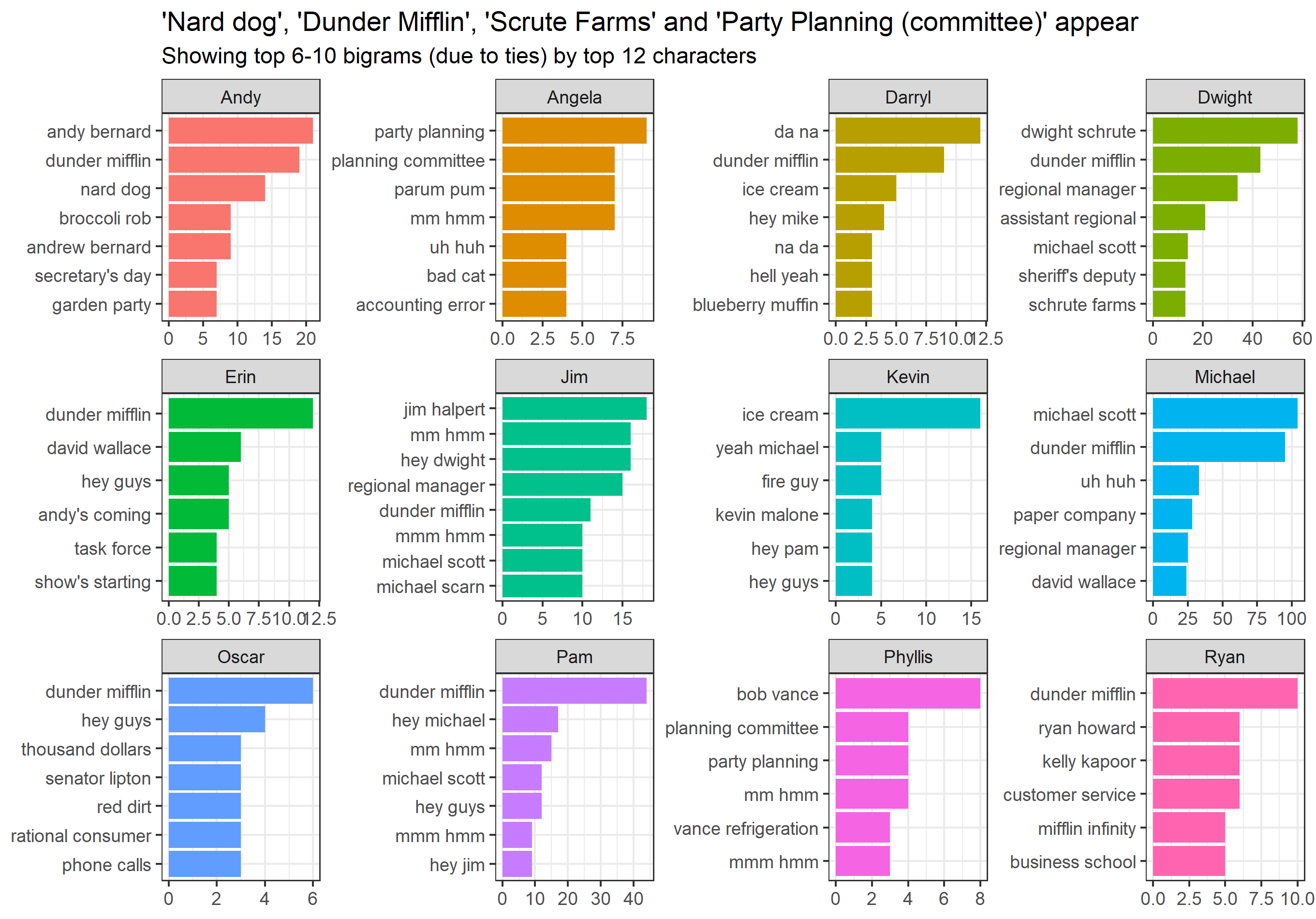
This is much better applicable for identification, as if we were to cover the names and simply read the lists of phrases, we’d be quite successful at correctly identifying who a certain phrase belonged to. Take a couple of examples: Andy’s ’Broccoli Rob’, Angela’s ’party planning (committee)’, Dwight’ farm’s name or Phyllis’ husband’s name, maybe ‘Senator Lipton’ coming from Oscar.
Simply taking the words, phrases (without stopwords) of characters made it quite easy for us to guess who they belonged to. When it came to phrases, we could almost be sure in our guesses. However, there’s one more method we’ll be discussing. The tf-idf is an algorithm that uses absolute word counts and relative word frequencies among all people to find words that clearly belong to one and only one character: it focuses on finding most unique-to-person words.
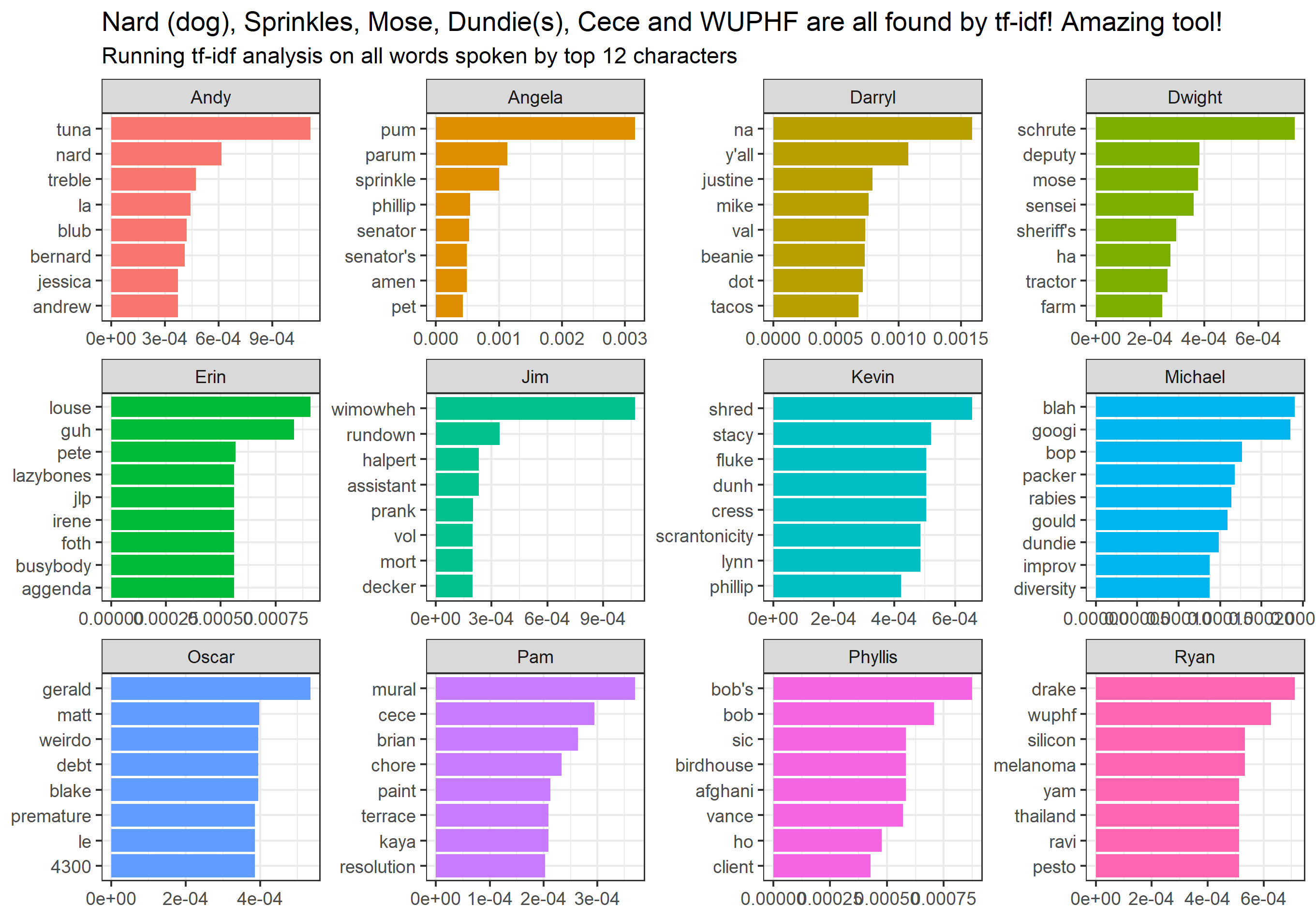
When looking at its results, The Office fans will be able to say who the terms belong to (almost) right away. By reading through the lists we can see that the tf-idf algorithm was able to extract most personal words. Take a look at some of them: Andy’s ’tuna’, ’treble’ and ’Jessica’; Darryl’s ’Justine’, ’Mike’ and ’beanie’; Ryan’s famous ’Wuphf’ or Pam’s ’Cece’ and ’mural’. Considering how easy it is to use the tf-idf method and how non-complex it is, it’s one of the most powerful tools NLP offers us.
So far, we have been looking at the top 12 character’s vocabularies, their most frequently used words and phrases and their most personal words. In the next, second chapter of this The Office blog we’ll be analyzing their overall sentiments, sentiments when talking to one another and we’ll try to find people who ‘sound alike’.
Kristof Rabay – Data Scientist